
|
||||||
|---|---|---|---|---|---|---|
| Home | The Company | Publications | Products | Links | Tips | Jobs |
|
|
||||||
|---|---|---|---|---|---|---|
| Home | The Company | Publications | Products | Links | Tips | Jobs |
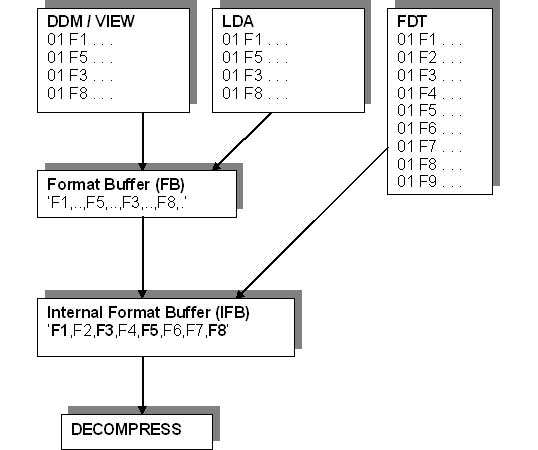
QuestionShould the field position in the format buffer or in the DDM be the same as the field position in the FDT?AnswerSteve Robinson responded that the physical positioning of simple fields should be based on frequency of use. ADABAS is field oriented, not record oriented. Thus, ADABAS must strip a record, field by field, to acquire the data it needs to send back to the calling program. ADABAS is smart enough to stop record stripping when it has data for all the requested fields. So, if you ask ADABAS for one field, and it is the last field in the record (FDT), ADABAS will have to strip the entire record in order to decompress the one field you need.By contrast, if you ask for five fields, and they are the first five in the record, ADABAS will only strip 5 fields, then return the data to you. An MU with 50 occurrences is just about as expensive to strip as 50 fields. Thus, given a single field and an MU field, the MU field would have to be used 50 times as much (assume usage of the two is always one or the other, not both) as the single field to justify placing the MU field first. Therefore, based on frequency of use, MU's and PE's are almost always found at the ends of records. It is also important, as Wolfgang Winter pointed out, when you have a spanned record that consists of 5 blocks and your format buffer (FB) includes a field from the 5th block, ADABAS must read every single block to retrieve that field because pointers to the next block are in the record header. Performance analysis by using STROBE (Compuware) showed a significant reduction in CPU time of the ADABAS modules ADANC7 (format translations) and ADANC8 (compression and decompression), when heavily used fields in a large FDT have been moved from the end to the beginning of the FDT. Graphic by Dieter Storr
For more information please see ADABAS Documentation
Back to
|
 Top Page
Top Page ADABAS Tips, Tricks, Techniques -- Overview
ADABAS Tips, Tricks, Techniques -- Overview